Data Wrangling with R
Kenny Darrell
Lead Data Scientist - Elder Research
October 17, 2016
What is Data Wrangling?
The process of manually converting data from one raw form into another that allows for more convenient consumption.
Where it fits in Analytics
- Data Persistence to house data
- Data Science to answer questions
- Data Products to visualize and consume results
- Data Wrangling makes all the above possible
Why, you ask?
- Data NEVER comes in the CORRECT format
- Data was collected for a DIFFERENT purpose
- Data comes from DISPARATE places
- Data CHANGES over time
- Data always has ERRORS in it
Data Janitor, unsung hero
Roughly 80% of time/effort

Pipes (brief detour)
- Easier if we think in steps
- The pipe (%>%) construct helps
- Left-to-right opposed to inside-out
- Easy to add steps in the sequence
Which is more readable
bop_on(scoop_up(hop_through(foo_foo, forest), field_mouse), head)
or
foo_foo %>%
hop_through(forest) %>%
scoop_up(field_mouse) %>%
bop_on(head)
Setup
options(stringsAsFactors = FALSE)
library(dplyr)
library(lubridate)
library(purrr)
library(ggplot2)
library(stringr)
Where do we start?
Always start with a question!
Which presidential candidate has been given more money?

The Data
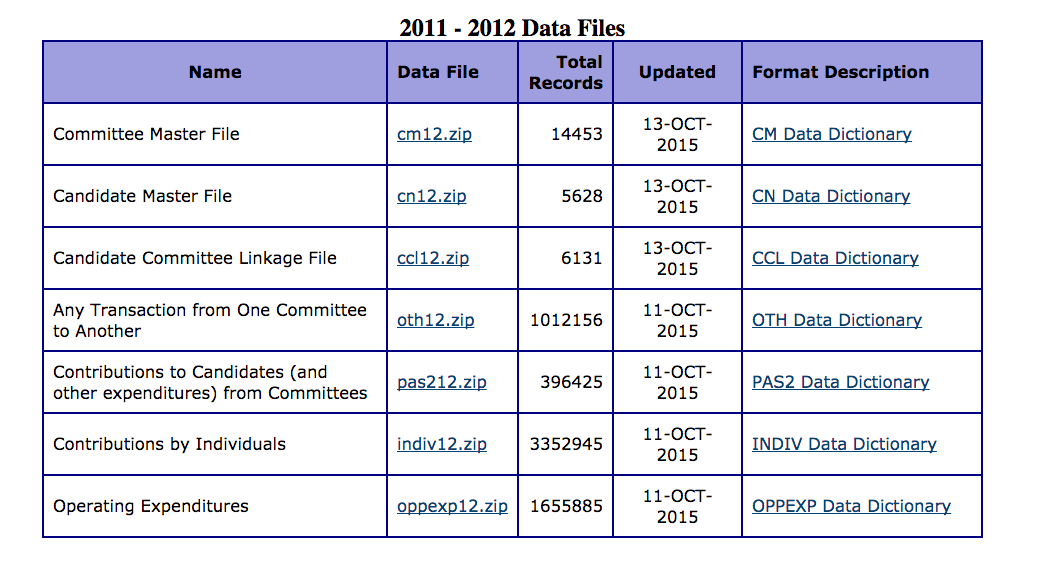
How it works
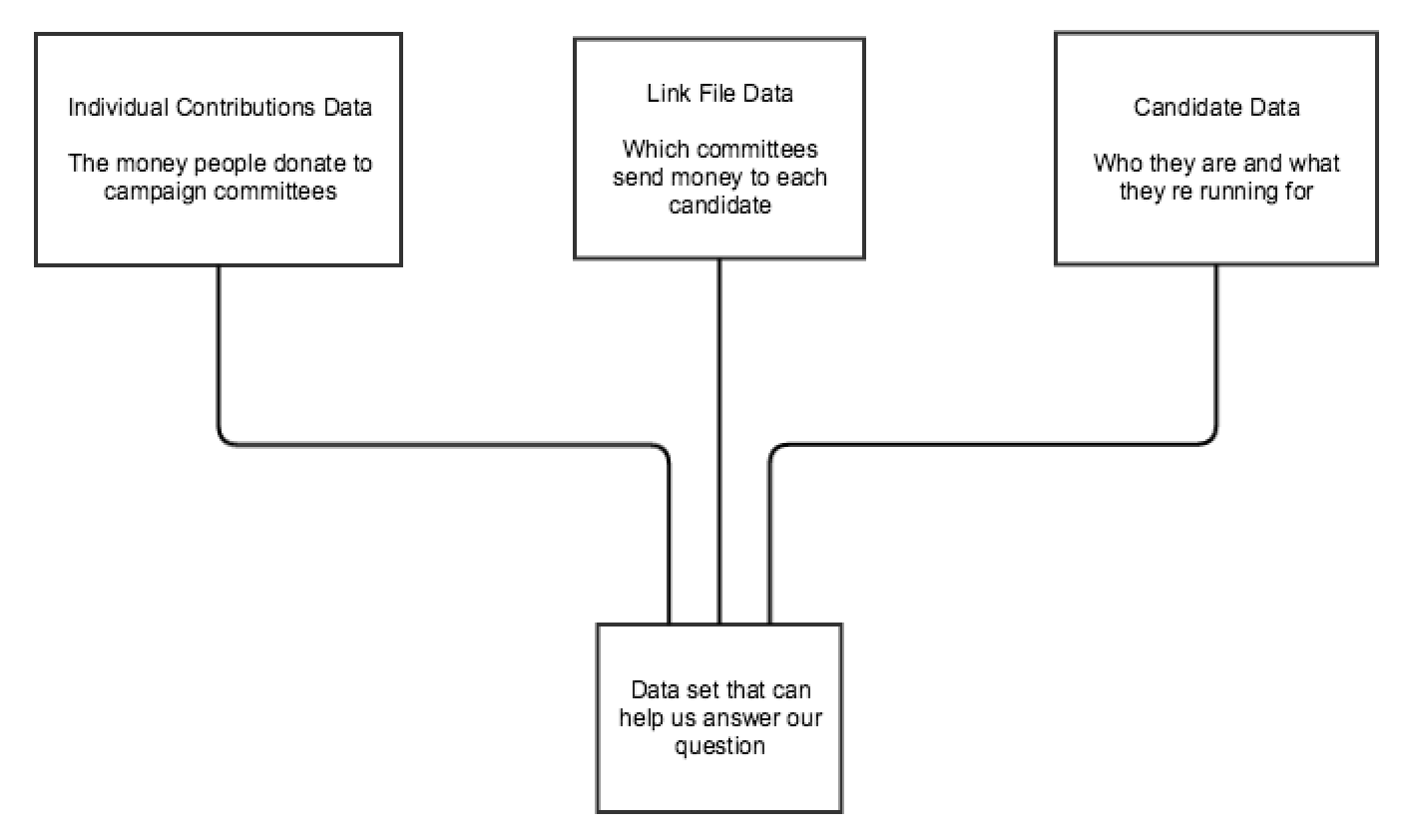
What does any of it mean
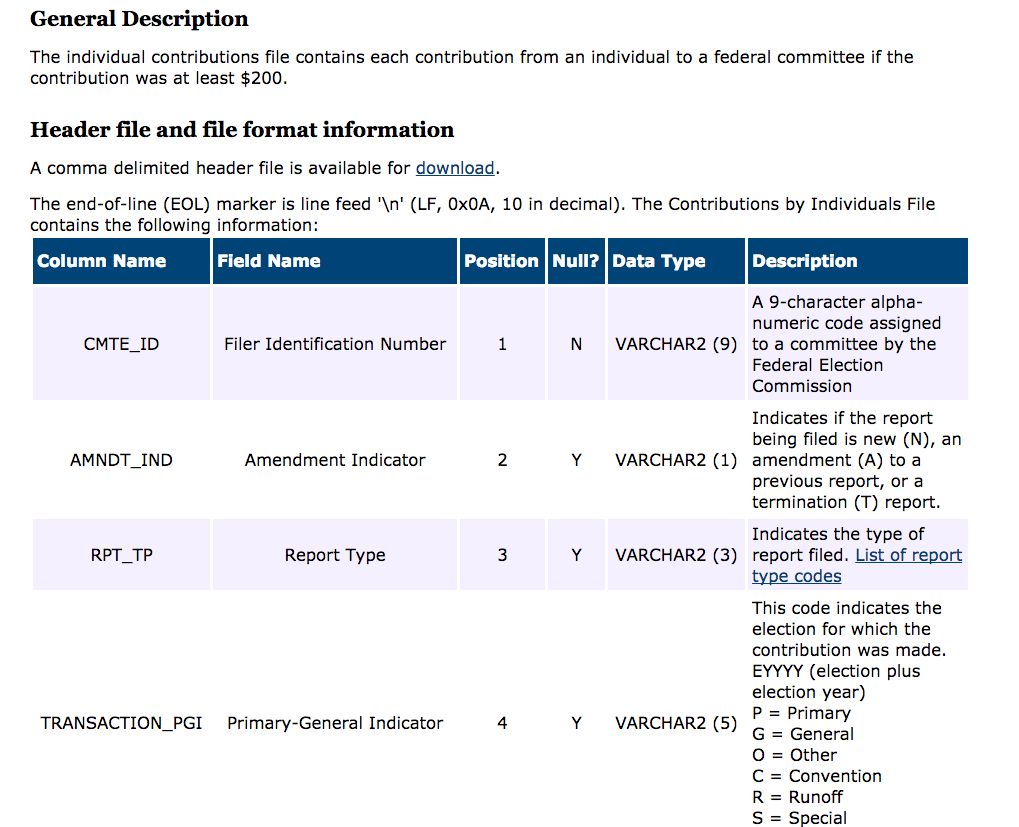
Load Individual Donations
Fair amount of work to import correctly
read.csv('itcont.txt', sep = '|', quote = "",
header = F, skipNul = T,
na.strings = '') -> ind
V1 V2 V3 V4 V5 V6 V7
1 C00004606 N M4 P 15951124869 15 IND
2 C00004606 N M4 P 15951124869 15 IND
3 C00004606 N M4 P 15951124869 15 IND
4 C00452383 N M4 P 15951124897 15 IND
5 C00452383 N M4 P 15951124897 15 IND
6 C00452383 N M4 P 15951124898 15 IND
The data has no names
names(ind) <- names(read.csv('indiv_header_file.csv'))
CMTE_ID AMNDT_IND RPT_TP TRANSACTION_PGI
1 C00004606 N M4 P
2 C00004606 N M4 P
3 C00004606 N M4 P
4 C00452383 N M4 P
5 C00452383 N M4 P
6 C00452383 N M4 P
Most of it is useless to us
Select
Decrease the width of your data
ind %>%
select(CMTE_ID, ENTITY_TP, TRANSACTION_DT,
TRANSACTION_AMT) -> ind
CMTE_ID ENTITY_TP TRANSACTION_DT
C00004606 IND 3102015
C00004606 IND 3302015
C00004606 IND 3302015
C00452383 IND 3112015
C00452383 IND 3022015
C00452383 IND 3022015
Just becuase it imported does not mean it is correct!
Date is not really date
str(ind$TRANSACTION_DT)
13058232 obs. :
$ TRANSACTION_DT : int 3102015 3302015 3302015 3112015 3022015 3022015 3232015 3302015 3272015 3272015 ...
Mutate to the Rescue
ind %>%
rename(date = TRANSACTION_DT) %>%
mutate(date = as.Date(mdy(date))) -> ind
CMTE_ID ENTITY_TP date TRANSACTION_AMT
C00004606 IND 2015-03-10 1000
C00004606 IND 2015-03-30 1000
C00004606 IND 2015-03-30 250
C00452383 IND 2015-03-11 500
C00452383 IND 2015-03-02 250
C00452383 IND 2015-03-02 200
Back to the Future (Sanity Check)
ind %>%
verify(date < today()) -> ind
Error in verify(., date < today()) :
verification failed! (NANA
Back to the Future (Sanity Check)
ind %>%
filter(date > today())
CMTE_ID ENTITY_TP TRANSACTION_AMT date
C00276311 IND 264 2016-12-31
C00042366 IND 60 2025-08-05
C00461046 IND 35 3016-04-26
C00578484 IND 20 2106-06-30
C00027466 IND 25 8216-08-01
Back to the Future (Sanity Check)
ind %>%
filter(date < today()) %>%
verify(date < today()) -> ind
Filter
Decrease the height of your data
ind %>%
filter(ENTITY_TP %in% c('IND', 'CAN')) %>%
select(-ENTITY_TP) -> ind
CMTE_ID TRANSACTION_AMT date
1 C00004606 1000 2015-03-10
2 C00004606 1000 2015-03-30
3 C00004606 250 2015-03-30
4 C00452383 500 2015-03-11
5 C00452383 250 2015-03-02
6 C00452383 200 2015-03-02
The process
- Load Data
- Give it correct names
- Select fields (columns) we need
- Filter rows (observations) that are relevant
- Rinse and repeat for other data sets
Remove code noise
add_names <- function(df, file) {
names(df) <- names(read.csv(file))
df
}
read_fec <- function(file) {
read.csv(file, sep = '|', skipNul = T,
na.strings = '', header = F,
quote = "")
}
Candidate Data
'cn.txt' %>%
read_fec %>%
add_names('cn_header_file.csv') %>%
select(CAND_ID, CAND_NAME, CAND_ELECTION_YR, CAND_OFFICE) -> cand
CAND_ID CAND_NAME CAND_ELECT_YR CAND_OFFICE
H0AK00097 COX, JOHN R. 2014 H
H0AL02087 ROBY, MARTHA 2016 H
H0AL02095 JOHN, ROBERT E JR 2016 H
H0AL05049 CRAMER, ROBERT E JR 2008 H
H0AL05163 BROOKS, MO 2016 H
H0AL06088 COOKE, STANLEY KYLE 2010 H
We want Presidential Candidates
cand %>%
filter(CAND_OFFICE == 'P') %>%
select(-CAND_OFFICE) -> cand
CAND_ID CAND_NAME CAND_ELECTION_YR
P00000679 CARROLL, JERRY LEON 2016
P00000729 MUZYK, GEORGE ALEXANDER 2000
P00001099 MARCINEK, ALOYSIUS R 2016
P00002295 BYERLEY, LESTER F JR 2012
P00003160 WELLS, THOMAS BAXTER 2016
P00003236 PRATTAS, JAMES 2012
Only care about this election
cand %>%
filter(CAND_ELECTION_YR == '2016') %>%
select(-CAND_ELECTION_YR) -> cand
CAND_ID CAND_NAME
P00000679 CARROLL, JERRY LEON
P00001099 MARCINEK, ALOYSIUS R
P00003160 WELLS, THOMAS BAXTER
P00003244 WINTERBOTTOM, THOMAS FRANCIS
P00003392 CLINTON, HILLARY RODHAM / KAINE, TIMOT
P00003640 LANCE-COUNCIL, TEMPERANCE ALESHA
Remove the running mates
cand$CAND_NAME %>%
str_split(" / ") %>%
map_chr(~ .[[1]]) -> cand$CAND_NAME
CAND_ID CAND_NAME
P00000679 CARROLL, JERRY LEON
P00001099 MARCINEK, ALOYSIUS R
P00003160 WELLS, THOMAS BAXTER
P00003244 WINTERBOTTOM, THOMAS FRANCIS
P00003392 CLINTON, HILLARY RODHAM
P00003640 LANCE-COUNCIL, TEMPERANCE ALESHA
Link Data
'ccl.txt' %>%
read_fec %>%
add_names('ccl_header_file.csv') %>%
select(CAND_ID, CMTE_ID) -> link
CAND_ID CMTE_ID
C00008227 C00623207
C00027466 C00623207
C00042366 C00624478
C00075820 C00624825
C00099267 C00623611
C00140590 C00624825
Turn three data sets into one
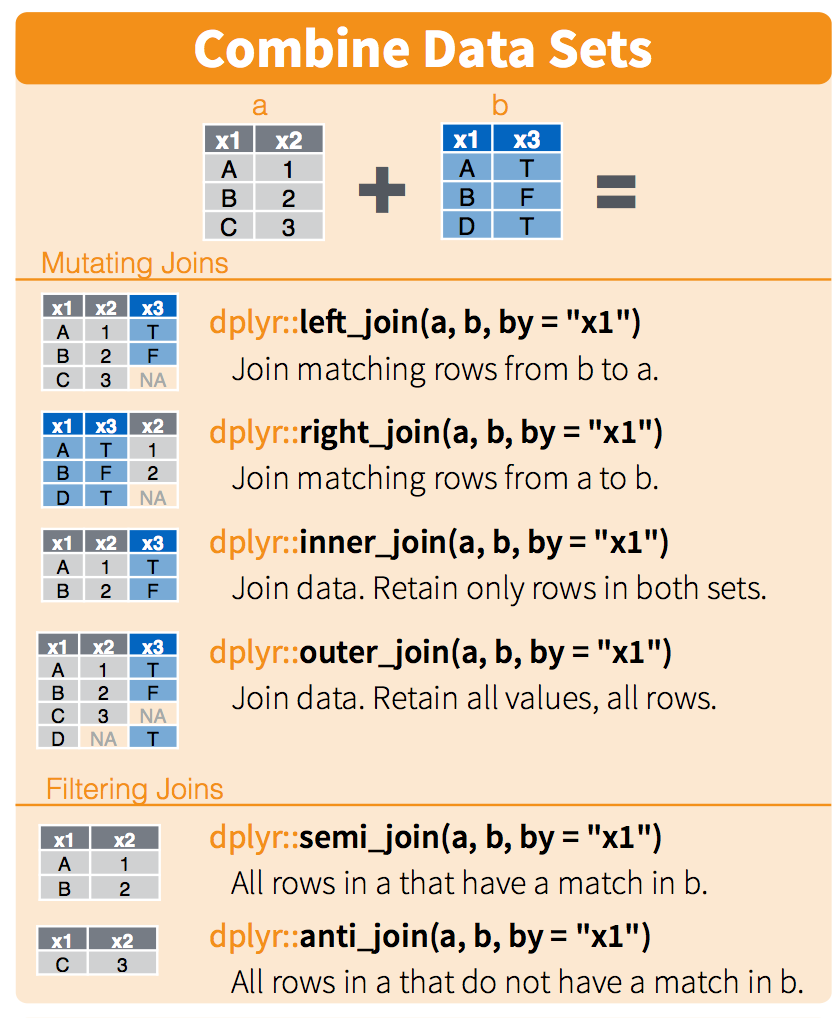
Inner Join
This will increase the width of the data
link %>%
inner_join(cand, by = c("CAND_ID")) -> df
CAND_ID CMTE_ID CAND_NAME
P00000679 C00214999 CARROLL, JERRY LEON
P00003160 C00571224 WELLS, THOMAS BAXTER
P00003244 C00549923 WINTERBOTTOM, THOMAS F
P00003392 C00577395 CLINTON, HILLARY RODHAM
P00003392 C00575795 CLINTON, HILLARY RODHAM
P00003392 C00570978 CLINTON, HILLARY RODHAM
Left Join
df %>%
left_join(ind, by = "CMTE_ID") -> df
CAND_ID CMTE_ID CAND_NAME
P00000679 C00214999 CARROLL, JERRY LEON
P00003160 C00571224 WELLS, THOMAS BAXTER
P00003244 C00549923 WINTERBOTTOM, THOMAS F
P00003392 C00577395 CLINTON, HILLARY RODHAM
P00003392 C00575795 CLINTON, HILLARY RODHAM
TRANSACTION_AMT date
NA NA
NA NA
NA NA
NA NA
2700 2015-04-27
Cleanup
df %>%
select(-CAND_ID, -CMTE_ID) -> df
CAND_NAME TRANSACTION_AMT date
CARROLL, JERRY LEON NA NA
WELLS, THOMAS BAXTER NA NA
WINTERBOTTOM, THOMAS FRANCIS NA NA
CLINTON, HILLARY RODHAM NA NA
CLINTON, HILLARY RODHAM 2700 2015-04-27
CLINTON, HILLARY RODHAM 2700 2015-04-28
Missing values
df %>%
filter(!is.na(TRANSACTION_AMT),
!is.na(date)) -> df
CAND_NAME TRANSACTION_AMT date
CLINTON, HILLARY RODHAM 2700 2015-04-27
CLINTON, HILLARY RODHAM 2700 2015-04-28
CLINTON, HILLARY RODHAM 201 2015-05-07
CLINTON, HILLARY RODHAM 250 2015-04-12
CLINTON, HILLARY RODHAM 2700 2015-05-01
CLINTON, HILLARY RODHAM 2700 2015-05-07
Too Verbose
df %>%
rename(name = CAND_NAME,
amount = TRANSACTION_AMT) -> df
name amount date
CLINTON, HILLARY RODHAM 2700 2015-04-27
CLINTON, HILLARY RODHAM 2700 2015-04-28
CLINTON, HILLARY RODHAM 201 2015-05-07
CLINTON, HILLARY RODHAM 250 2015-04-12
CLINTON, HILLARY RODHAM 2700 2015-05-01
CLINTON, HILLARY RODHAM 2700 2015-05-07
Annoying Names
df$name %>%
str_split(", ") %>%
map_chr(~ paste(.[[2]], .[[1]])) -> df$name
name amount date
1 HILLARY RODHAM CLINTON 2700 2015-04-27
2 HILLARY RODHAM CLINTON 2700 2015-04-28
3 HILLARY RODHAM CLINTON 201 2015-05-07
4 HILLARY RODHAM CLINTON 250 2015-04-12
5 HILLARY RODHAM CLINTON 2700 2015-05-01
6 HILLARY RODHAM CLINTON 2700 2015-05-07
Who?
df %>%
group_by(name) %>%
summarise(obs = n()) -> popular
name obs
1 ANDREW DANIEL BASIAGO 6
2 AUSTIN WADE PETERSEN 186
3 BENJAMIN S CARSON 218825
4 BERNARD SANDERS 505994
5 BOB WHITAKER 2
6 BOBBY JINDAL 761
7 CARLY FIORINA 27635
8 CHRISTOPHER J CHRISTIE 5764
9 COLIN B DOYLE 1
10 DALE H CHRISTENSEN 3
11 DARRELL LANE CASTLE 10
12 DONALD J. TRUMP 73126
13 ELIJAH D MANLEY 15
14 EVAN MCMULLIN 254
15 GARY JOHNSON 6577
16 GEORGE E PATAKI 333
17 HILLARY RODHAM CLINTON 1138214
18 JAMES R PERRY 874
19 JAMES S GILMORE 80
20 JAMES WEBB 749
21 JEB BUSH 23450
22 JEFF GEORGE 4
23 JILL STEIN 4392
24 JOHN R KASICH 25138
25 JUDD WEISS 4
26 LAWRENCE LESSIG 2271
27 LINCOLN DAVENPORT CHAFEE 36
28 LINDSEY O GRAHAM 4243
29 LIZA DAWN CHERRICKS 2
30 MARCO RUBIO 91540
31 MARK EVERSON 34
32 MARTIN JOSEPH O'MALLEY 4572
33 MIKE HUCKABEE 6411
34 PETER ALAN SKEWES 8
35 RAFAEL EDWARD CRUZ 397788
36 RAND PAUL 30568
37 RICHARD J. SANTORUM 1676
38 ROQUE ROCKY DE LA FUENTE 12
39 SCOTT WALKER 6740
40 WILLIAM P KREML 11
41 WILLIE WILSON 50
More readable
popular %>%
top_n(10, obs) %>%
arrange(-obs) -> most_popular
name obs
HILLARY RODHAM CLINTON 1138214
BERNARD SANDERS 505994
RAFAEL EDWARD CRUZ 397788
BENJAMIN S CARSON 218825
MARCO RUBIO 91540
DONALD J. TRUMP 73126
RAND PAUL 30568
CARLY FIORINA 27635
JOHN R KASICH 25138
JEB BUSH 23450
Shorten the list
df %>%
semi_join(most_popular, by = 'name') -> df
Aggregations
df %>%
group_by(name, date) %>%
summarise(total = sum(amount)) -> df
name date total
BENJAMIN S CARSON 2015-03-03 90575
BENJAMIN S CARSON 2015-03-04 58337
BENJAMIN S CARSON 2015-03-05 23878
BENJAMIN S CARSON 2015-03-06 7150
BENJAMIN S CARSON 2015-03-08 13200
Add in missing days
allDates <- data.frame(
date = as.Date(min(df$date):max(df$date),
origin = origin))
df %>% split(.$name) %>%
map( ~ full_join(., cbind(allDates,
name = .$name[1]),
by = c("name", "date"))) %>%
bind_rows %>%
arrange(name, date) -> df
name date total
BENJAMIN S CARSON 2014-11-19 NA
BENJAMIN S CARSON 2014-11-20 NA
BENJAMIN S CARSON 2014-11-21 NA
BENJAMIN S CARSON 2014-11-22 NA
BENJAMIN S CARSON 2014-11-23 NA
Zero
df$total <- ifelse(is.na(df$total),
0, df$total)
name date total
BENJAMIN S CARSON 2014-11-19 0
BENJAMIN S CARSON 2014-11-20 0
BENJAMIN S CARSON 2014-11-21 0
BENJAMIN S CARSON 2014-11-22 0
BENJAMIN S CARSON 2014-11-23 0
BENJAMIN S CARSON 2014-11-24 0
Order them
df %>%
arrange(name, date) -> df
name date total
BENJAMIN S CARSON 2014-11-19 0
BENJAMIN S CARSON 2014-11-20 0
BENJAMIN S CARSON 2014-11-21 0
BENJAMIN S CARSON 2014-11-22 0
BENJAMIN S CARSON 2014-11-23 0
BENJAMIN S CARSON 2014-11-24 0
Running total
df %>%
group_by(name) %>%
mutate(cum_tot = cumsum(total)) -> tot
name date total cum_tot
BENJAMIN S CARSON 2014-11-19 0 0
BENJAMIN S CARSON 2014-11-20 0 0
BENJAMIN S CARSON 2014-11-21 0 0
BENJAMIN S CARSON 2014-11-22 0 0
BENJAMIN S CARSON 2014-11-23 0 0
BENJAMIN S CARSON 2014-11-24 0 0
BENJAMIN S CARSON 2014-11-25 0 0
BENJAMIN S CARSON 2014-11-26 0 0
BENJAMIN S CARSON 2014-11-27 0 0
BENJAMIN S CARSON 2014-11-28 0 0
ggplot(tot, aes(x = date, y = cum_tot,
color = name, group = name)) + geom_line()
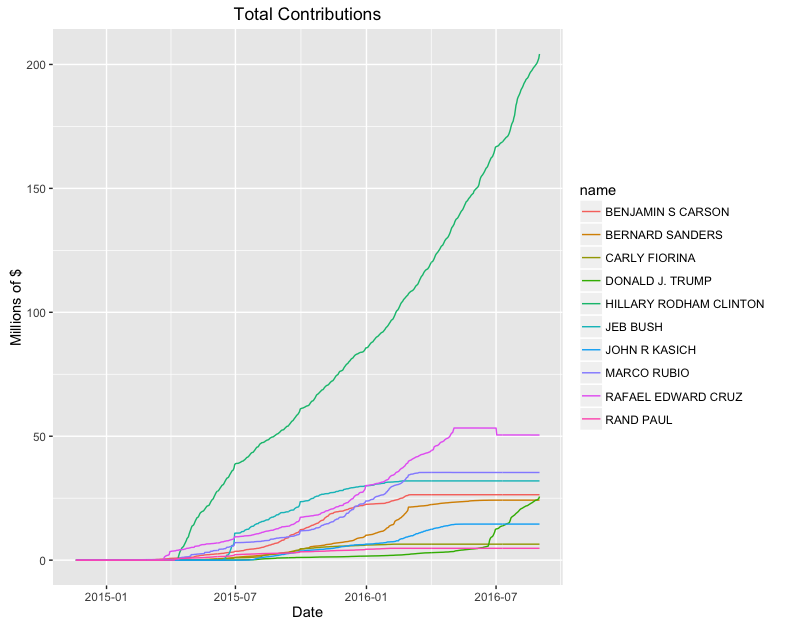
Total Money
tot %>%
group_by(name) %>%
summarise(max = max(cum_tot)) %>%
arrange(desc(max)) -> totals
name max
HILLARY RODHAM CLINTON 204225991
RAFAEL EDWARD CRUZ 53317686
MARCO RUBIO 35386733
JEB BUSH 31971222
BENJAMIN S CARSON 26399305
DONALD J. TRUMP 25660719
BERNARD SANDERS 24206222
JOHN R KASICH 14549688
CARLY FIORINA 6447807
RAND PAUL 4778704
tot %>%
anti_join(totals %>%
top_n(1, max), by = 'name') %>%
ggplot(aes(x = date, y = cum_tot,
color = name, group = name)) + geom_line()
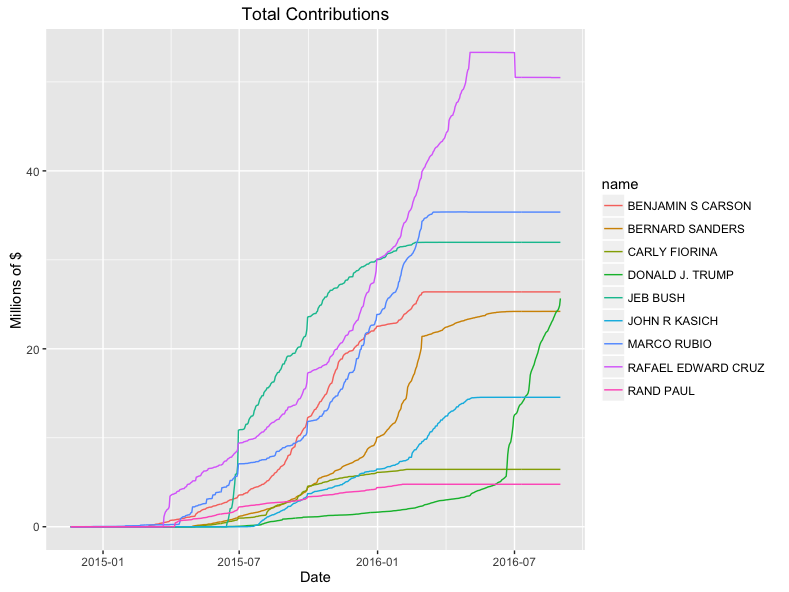
Final Result
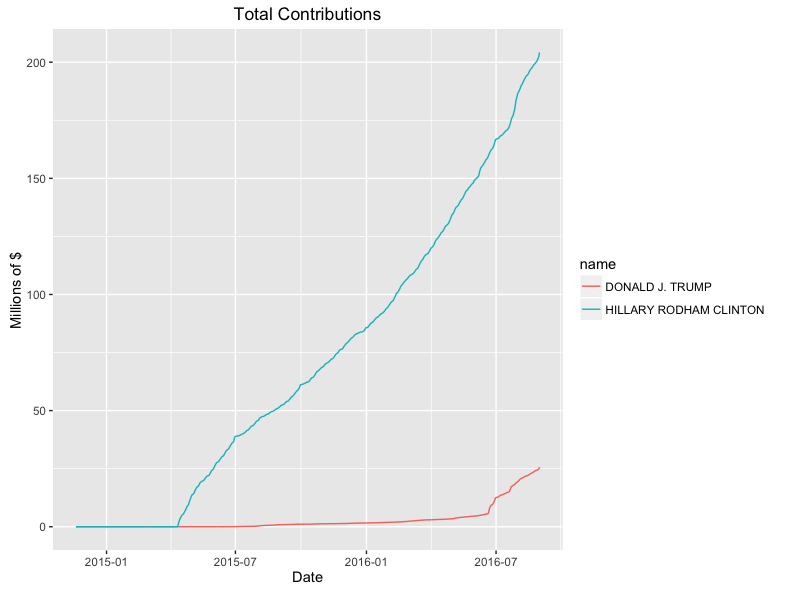
Did we answer the question?
Yes, but it took many steps to answer a fairly simple question!