The record linkage problem is a nasty beast that pops its head up when you have disperate data sources. If you have ever encountered it yourself then you have shared in my frustrations. It can be a real pain. In all analytics work you get side tracked with cleansing issues, but this one is a real pain becuase it often requires its own modeling process. This can then carry some uncertaininty forward into all of the downstream analysis. As I work with it here and there I want to persist some thoughts, definitions and a few code snippets in this post.
The problem goes by many different names and depending on the level of rigor can have many phases.
AKA
- Merge purge
- List washing
- Data matching
- Enitity resolution
- Many others
Some ground can be made by defining some of the terms in this area.
Entity - A real world object. This can be a person, place or anything else. It does not need to be a physichal thing.
Attributes - An entity has various types of data that can be attached to it. A person has a first name a last and a birth date.
Reference - Data contains observations that are filled with attributes that refer to real world entities.
When we create a database we spend some time ensuring that we know what entities exist and we clearly define them and have the ability to add a uniqness constraint. Then we create a key for each entity and then istead of ever using the enitity we use the key so we are using a reference to the entity. When data comes from disperate sources we no longer have a key that clearly and uniquely shows the reference entity. There is more than just one challange here.
Deduplication - Remove redundent references to the same entity in one data source. This normalization will mean that we have a unique set of entities. This was mentioned previosly as the part of creating a key in a database.
Canonicalization - This creates the most complete record. This is similar to deduplication except that the duplicate versions may have more or less information than others, and the goal is to create the most full form of the entity.
Record Linkage - When we have two different sources of of deduplicated and canonicalized data sets and we need determine which observations in one set should be linked to that in another.
Disambiguation or Referenceing - To match a noisy set to a deduped set. This can also add extra information to contribute to a more complete reference entity.
This source has more information all on all of these but the highlight is the that it provides this great image.
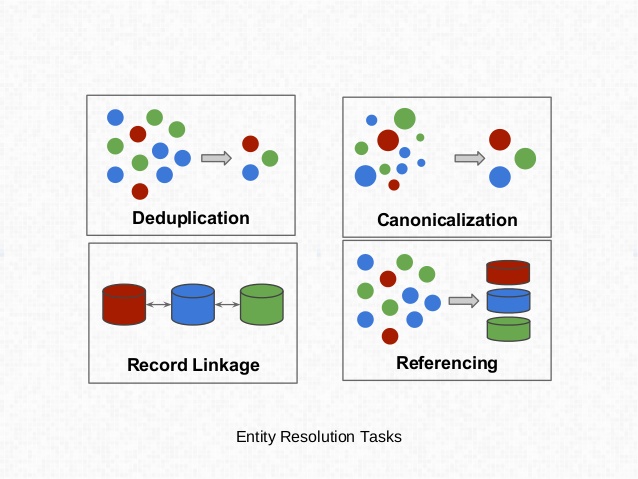
In data science the problem is more often called entity resolution. This term can mean many things. This source lays out this larger overall process. I have often thought that all of this was more Master Data Management.
- Entity Reference Extraction
- Entity Reference Preperation
- Entity Reference Resolution
- Entity Identity Management
- Entity Relationship Analysis
The first one is often related to text mining, where you have to extrat a reference to an entity from some form of free text. If you work with disperate structured data sets this one may be less common. The next is the data preperation phase. This will be tasks similar to the above deduplication and canonicalization. The entity reference phase is the part that is commonly called record linkage, where we match references that share similar attributes. What we hope to do is find to references to the same entity and link them. The next phase is the identity management, this is where we resolve cand mantian the real world entites as encoded data.
One item to note is identity resolution is different than entity resolution.
We can determine if two sets of fingerprints are for the same or different suspect without ever knowing the identity. Thus we can say that two crimes scenes are the same criminal or not but have no idea who the criminal really is. This is entity resolution.
If we have a fingerprint from a crime scene and get a hit in a database of previosly incarcerated entities then we know the identity. This is identity resolution.
How we resolve the entites is based on Linking which can be done in a few different ways:
- Direct Matching
- Transitive Linking
- Linking by Association
- Asserted Linking
Direct matching means to compare attributes and can be done via
- Deterministic matching - all attributes agree
- Probabilistic matching - certain combinations agree
- Fuzzy matching - agree can really be approximate
Transitive Linking is similar to the mathematical notion, if A links to B and B links to C, then transitive linking implies that A also links to C.
Association is when we have multiple types of entities, say people and houses. If we know only one person lives at a house we can say that two sources with people and there homes, that if the home is resolved and linked then the people attached to those houses are linked as well.
Assertion is done by a person and can be also be called knowldege based.
Some other terms you will here.
- Edit Distance
- Levenshtein Distance
- Jaro-Winkler Distance
- Fellegi-Sunter Model
- Swoosh Algorithm
No matter which problem we are solving we have a few basic parameters to keep in mind.
R - The number of records M - The set of matches N - The set of non-matches E - The set of entities L - The set of links
We also need to recognize what problem we are solving. If we are doing record linkage it really means we have two deduplicated and canonical sources so we could at most have on link per entity, but we may have many matches. In other problems such as deduplication we may have many mancy valid matches. It is common though that we have few real links, this is because for any set of data we have some number of observations in one set, call it A and a similar count in the second, call it B. We have A * B possible matches, but most should nto be matched. We can take the true matches as true positives and similar for each of the other supervised learnign outcomes, false postive, false negative and true negatives and create all the same performance measures.
Example
options(stringsAsFactors = FALSE)
# Load libraries
library(httr)
library(XML)
library(dplyr)
library(rvest)
library(lubridate)
library(purrr)
library(fuzzyjoin)This gets a full set of all NBA players. We can consider this to be a full set of identities. It has already been deduplicated, but it won’t be fully canonicalized.
'http://www.basketball-reference.com/players/' %>%
paste0(letters[-24]) %>%
map_df(~readHTMLTable(.)[[1]]) -> players
head(players)## Source: local data frame [6 x 8]
##
## Player From To Pos Ht Wt Birth Date
## (chr) (chr) (chr) (chr) (chr) (chr) (chr)
## 1 Alaa Abdelnaby 1991 1995 F-C 6-10 240 June 24, 1968
## 2 Zaid Abdul-Aziz 1969 1978 C-F 6-9 235 April 7, 1946
## 3 Kareem Abdul-Jabbar* 1970 1989 C 7-2 225 April 16, 1947
## 4 Mahmoud Abdul-Rauf 1991 2001 G 6-1 162 March 9, 1969
## 5 Tariq Abdul-Wahad 1998 2003 F 6-6 223 November 3, 1974
## 6 Shareef Abdur-Rahim 1997 2008 F 6-9 225 December 11, 1976
## Variables not shown: College (chr)Now we need to do some data preperation on the table to make it more usable. I am also going to remove a dew fields that we are not going to use, but in reality you would keep these for complete canonicalization.
players %>%
mutate(From = as.numeric(From),
To = as.numeric(To)) %>%
rename(name = Player) %>%
select(-`Birth Date`, -College, -Ht, -Wt) -> players
# This denotes players that are in the Hall of Fame.
players$name <- gsub('*', '', players$name, fixed = T)
head(players)## Source: local data frame [6 x 4]
##
## name From To Pos
## (chr) (dbl) (dbl) (chr)
## 1 Alaa Abdelnaby 1991 1995 F-C
## 2 Zaid Abdul-Aziz 1969 1978 C-F
## 3 Kareem Abdul-Jabbar 1970 1989 C
## 4 Mahmoud Abdul-Rauf 1991 2001 G
## 5 Tariq Abdul-Wahad 1998 2003 F
## 6 Shareef Abdur-Rahim 1997 2008 FNow we need to aqcuire a dataset to match against.
'http://espn.go.com/nba/boxscore?gameId=290324004' %>%
read_html %>%
html_nodes('table') %>%
html_nodes('.name') %>%
html_text -> game
head(game)## [1] "starters" "A. McDyessPF" "T. PrinceSF" "K. BrownC"
## [5] "R. StuckeyPG" "A. AfflaloSG"We obviously have to do some data preperation on this as well! This is really turning the list into a data.frame and removing things that are not names and rows that are really just spaces.
game %>%
data.frame(game = .) %>%
filter(!game %in% c('starters', 'bench', 'TEAM')) %>%
filter(nchar(game) > 1) -> game
head(game)## game
## 1 A. McDyessPF
## 2 T. PrinceSF
## 3 K. BrownC
## 4 R. StuckeyPG
## 5 A. AfflaloSG
## 6 W. SharpePFWe need to seperate all of the text into its own fields. We must also create fields that exist in the set we are trying to match against.
game$f_init <- sapply(strsplit(game$game, '. ', fixed = T), `[[`, 1)
game$name <- sapply(strsplit(game$game, '. ', fixed = T), `[[`, 2)
game$pos <- NA
for (i in c('PG$', 'SG$', 'G$', 'PF$', 'SF$', 'C$')) {
game$pos <- ifelse(grepl(i, game$name), i, game$pos)
game$name <- gsub(i, '', game$name)
}
game$pos <- gsub('$', '', game$pos, fixed = T)
game %>% mutate(year = 2009) %>%
select(-game) %>%
rename(last = name) -> game
head(game)## f_init last pos year
## 1 A McDyess PF 2009
## 2 T Prince SF 2009
## 3 K Brown C 2009
## 4 R Stuckey PG 2009
## 5 A Afflalo SG 2009
## 6 W Sharpe PF 2009Now we need to add to the original data the fields which are needed to match against.
# 'last, first' -> 'last', 'first'
players$first <- sapply(strsplit(players$name, ' ', fixed = T), `[[`, 1)
players$last <- sapply(strsplit(players$name, ' ', fixed = T), `[[`, 2)
players$f_init <- substr(players$first, 1, 1)
head(players)## Source: local data frame [6 x 7]
##
## name From To Pos first last f_init
## (chr) (dbl) (dbl) (chr) (chr) (chr) (chr)
## 1 Alaa Abdelnaby 1991 1995 F-C Alaa Abdelnaby A
## 2 Zaid Abdul-Aziz 1969 1978 C-F Zaid Abdul-Aziz Z
## 3 Kareem Abdul-Jabbar 1970 1989 C Kareem Abdul-Jabbar K
## 4 Mahmoud Abdul-Rauf 1991 2001 G Mahmoud Abdul-Rauf M
## 5 Tariq Abdul-Wahad 1998 2003 F Tariq Abdul-Wahad T
## 6 Shareef Abdur-Rahim 1997 2008 F Shareef Abdur-Rahim SNow we can try to resolve who played in this game against all NBA players. Is this entity resolution or identity resolution? Since we considered the set of all NBA players as the reference list this is more of an identity resolution problem, we need to match each observation to the real reference entity. This also adds a constraint that we cannot create multiple links for any refrence entity.
m <- players %>% select(name, Pos, last, first, f_init, From, To)
game %>% left_join(m) %>% as.data.frame()## Joining by: c("f_init", "last")## f_init last pos year name Pos first From To
## 1 A McDyess PF 2009 Antonio McDyess F-C Antonio 1996 2011
## 2 T Prince SF 2009 Tayshaun Prince F Tayshaun 2003 2016
## 3 K Brown C 2009 Kedrick Brown G Kedrick 2002 2005
## 4 K Brown C 2009 Kwame Brown F Kwame 2002 2013
## 5 R Stuckey PG 2009 Rodney Stuckey G Rodney 2008 2016
## 6 A Afflalo SG 2009 Arron Afflalo G Arron 2008 2016
## 7 W Sharpe PF 2009 Walter Sharpe F Walter 2009 2009
## 8 A Johnson PF 2009 Alexander Johnson F Alexander 2007 2008
## 9 A Johnson PF 2009 Amir Johnson F Amir 2006 2016
## 10 A Johnson PF 2009 Andy Johnson F-G Andy 1959 1962
## 11 A Johnson PF 2009 Anthony Johnson G Anthony 1998 2010
## 12 A Johnson PF 2009 Armon Johnson G Armon 2011 2012
## 13 A Johnson PF 2009 Arnie Johnson F-C Arnie 1949 1953
## 14 A Johnson PF 2009 Avery Johnson G Avery 1989 2004
## 15 J Maxiell PF 2009 Jason Maxiell F Jason 2006 2015
## 16 W Heinrich PF 2009 <NA> <NA> <NA> NA NA
## 17 R Wallace PF 2009 Rasheed Wallace F-C Rasheed 1996 2013
## 18 R Wallace PF 2009 Red Wallace G Red 1947 1947
## 19 W Bynum PG 2009 Will Bynum G Will 2006 2015
## 20 R Hamilton SG 2009 Ralph Hamilton G-F Ralph 1949 1949
## 21 R Hamilton SG 2009 Richard Hamilton G-F Richard 2000 2013
## 22 R Hamilton SG 2009 Roy Hamilton G Roy 1980 1981
## 23 A Iverson SG 2009 Allen Iverson G Allen 1997 2010
## 24 T Thomas PF 2009 Terry Thomas F Terry 1976 1976
## 25 T Thomas PF 2009 Tim Thomas F Tim 1998 2010
## 26 T Thomas PF 2009 Tyrus Thomas F Tyrus 2007 2015
## 27 J Salmons SF 2009 John Salmons G John 2003 2015
## 28 J Noah C 2009 Joakim Noah C Joakim 2008 2016
## 29 K Hinrich SG 2009 Kirk Hinrich G Kirk 2004 2016
## 30 B Gordon SG 2009 Ben Gordon G Ben 2005 2015
## 31 L Johnson PF 2009 Larry Johnson G Larry 1978 1978
## 32 L Johnson PF 2009 Larry Johnson F Larry 1992 2001
## 33 L Johnson PF 2009 Lee Johnson F Lee 1981 1981
## 34 L Johnson PF 2009 Linton Johnson F Linton 2004 2009
## 35 T Thomas PF 2009 Terry Thomas F Terry 1976 1976
## 36 T Thomas PF 2009 Tim Thomas F Tim 1998 2010
## 37 T Thomas PF 2009 Tyrus Thomas F Tyrus 2007 2015
## 38 L Deng SF 2009 Luol Deng F Luol 2005 2016
## 39 A Gray C 2009 Aaron Gray C Aaron 2008 2014
## 40 J James C 2009 Jerome James C Jerome 1999 2009
## 41 B Miller C 2009 Bill Miller F Bill 1949 1949
## 42 B Miller C 2009 Bob Miller F Bob 1984 1984
## 43 B Miller C 2009 Brad Miller C Brad 1999 2012
## 44 D Rose PG 2009 Derrick Rose G Derrick 2009 2016
## 45 A Roberson SG 2009 Andre Roberson G-F Andre 2014 2016
## 46 A Roberson SG 2009 Anthony Roberson G Anthony 2006 2009
## 47 L Hunter SG 2009 Les Hunter F-C Les 1965 1973
## 48 L Hunter SG 2009 Lindsey Hunter G Lindsey 1994 2010We are getting back more players than we would expect. This means we have more matches than links that we need to create. Or in data science speek we have some things in M, the set of matches that should be in N, the non-matches, so a few false positves. We can take additional steps to remove these flase positves, but this can also contribute to more false negatives. We can see that we are not fully utilizing all of the information. Arnie Johnson played from 1949 to 1953, so it is not a valid match for this game. We can utilize the time of the game alongside the career window of a player to help reduce the false positives. Since we considered this to be Identity resoloution becuase the the first list is the authoriative list of NBA players. We also know that we can only have one player from the game that should be matched to this list. This is not a canonicalization problem where we may have the same entity many times with different information that we want to pull together. We also know that we need a link for each.
m <- players %>% filter(From <= 2009, To >= 2009) %>%
select(name, Pos, last, first, f_init)
game %>% left_join(m) %>% as.data.frame()## Joining by: c("f_init", "last")## f_init last pos year name Pos first
## 1 A McDyess PF 2009 Antonio McDyess F-C Antonio
## 2 T Prince SF 2009 Tayshaun Prince F Tayshaun
## 3 K Brown C 2009 Kwame Brown F Kwame
## 4 R Stuckey PG 2009 Rodney Stuckey G Rodney
## 5 A Afflalo SG 2009 Arron Afflalo G Arron
## 6 W Sharpe PF 2009 Walter Sharpe F Walter
## 7 A Johnson PF 2009 Amir Johnson F Amir
## 8 A Johnson PF 2009 Anthony Johnson G Anthony
## 9 J Maxiell PF 2009 Jason Maxiell F Jason
## 10 W Heinrich PF 2009 <NA> <NA> <NA>
## 11 R Wallace PF 2009 Rasheed Wallace F-C Rasheed
## 12 W Bynum PG 2009 Will Bynum G Will
## 13 R Hamilton SG 2009 Richard Hamilton G-F Richard
## 14 A Iverson SG 2009 Allen Iverson G Allen
## 15 T Thomas PF 2009 Tim Thomas F Tim
## 16 T Thomas PF 2009 Tyrus Thomas F Tyrus
## 17 J Salmons SF 2009 John Salmons G John
## 18 J Noah C 2009 Joakim Noah C Joakim
## 19 K Hinrich SG 2009 Kirk Hinrich G Kirk
## 20 B Gordon SG 2009 Ben Gordon G Ben
## 21 L Johnson PF 2009 Linton Johnson F Linton
## 22 T Thomas PF 2009 Tim Thomas F Tim
## 23 T Thomas PF 2009 Tyrus Thomas F Tyrus
## 24 L Deng SF 2009 Luol Deng F Luol
## 25 A Gray C 2009 Aaron Gray C Aaron
## 26 J James C 2009 Jerome James C Jerome
## 27 B Miller C 2009 Brad Miller C Brad
## 28 D Rose PG 2009 Derrick Rose G Derrick
## 29 A Roberson SG 2009 Anthony Roberson G Anthony
## 30 L Hunter SG 2009 Lindsey Hunter G LindseyThis helped clear away a lot of the false matches. Since this was done in a deterministic way there is no way to take the most likely, high proabability match. It was rule driven so we needed to refine the rules.
One thing we see here is that we have a few matches that occur many times. This is becuase our input was not unique.
game[duplicated(game), ]## f_init last pos year
## 20 T Thomas PF 2009So this guy appears twice. Really one is named Tim and the other Tyrus. There is no way to resolve this given this data frame. We could add further info if we had further sets of data that denote which team each person played for or even the height and weight. We have position here, which in other cases could work but these players are both point gaurds.
game %>% left_join(m) %>% as.data.frame() %>% distinct## Joining by: c("f_init", "last")## f_init last pos year name Pos first
## 1 A McDyess PF 2009 Antonio McDyess F-C Antonio
## 2 T Prince SF 2009 Tayshaun Prince F Tayshaun
## 3 K Brown C 2009 Kwame Brown F Kwame
## 4 R Stuckey PG 2009 Rodney Stuckey G Rodney
## 5 A Afflalo SG 2009 Arron Afflalo G Arron
## 6 W Sharpe PF 2009 Walter Sharpe F Walter
## 7 A Johnson PF 2009 Amir Johnson F Amir
## 8 A Johnson PF 2009 Anthony Johnson G Anthony
## 9 J Maxiell PF 2009 Jason Maxiell F Jason
## 10 W Heinrich PF 2009 <NA> <NA> <NA>
## 11 R Wallace PF 2009 Rasheed Wallace F-C Rasheed
## 12 W Bynum PG 2009 Will Bynum G Will
## 13 R Hamilton SG 2009 Richard Hamilton G-F Richard
## 14 A Iverson SG 2009 Allen Iverson G Allen
## 15 T Thomas PF 2009 Tim Thomas F Tim
## 16 T Thomas PF 2009 Tyrus Thomas F Tyrus
## 17 J Salmons SF 2009 John Salmons G John
## 18 J Noah C 2009 Joakim Noah C Joakim
## 19 K Hinrich SG 2009 Kirk Hinrich G Kirk
## 20 B Gordon SG 2009 Ben Gordon G Ben
## 21 L Johnson PF 2009 Linton Johnson F Linton
## 22 L Deng SF 2009 Luol Deng F Luol
## 23 A Gray C 2009 Aaron Gray C Aaron
## 24 J James C 2009 Jerome James C Jerome
## 25 B Miller C 2009 Brad Miller C Brad
## 26 D Rose PG 2009 Derrick Rose G Derrick
## 27 A Roberson SG 2009 Anthony Roberson G Anthony
## 28 L Hunter SG 2009 Lindsey Hunter G LindseyThere is another similar collision with A Johnson, but this one we could use the position to resolve. We also have another that gets no match. This is because a differnt name is used. We can see all sorts of problems here. We can obviously do some things to make this work in this case but in the reality of the problem we would see new sets of data coming in that we may have similar issues, but nobody to use Wikipedia or ESPN to figure out what to do. This is the point that we think about probabilistic links. We need to qualify the strength of a match then link the highest. This will have errors, but all data science has errors. All models are wrong, but some are useful!
get_pl <- function(game, year) {
game %>%
paste0('http://espn.go.com/nba/boxscore?gameId=', .) %>%
read_html %>%
html_nodes('table') %>%
html_nodes('.name') %>%
html_text %>%
data.frame(game = .) %>%
filter(!game %in% c('starters', 'bench', 'TEAM')) %>%
filter(nchar(game) > 1) -> game
game$f_init <- sapply(strsplit(game$game, '. ', fixed = T), `[[`, 1)
game$name <- sapply(strsplit(game$game, '. ', fixed = T), `[[`, 2)
game$pos <- NA
for (i in c('PG$', 'SG$', 'G$', 'PF$', 'SF$', 'C$')) {
game$pos <- ifelse(grepl(i, game$name), i, game$pos)
game$name <- gsub(i, '', game$name)
}
game$pos <- gsub('$', '', game$pos, fixed = T)
game %>% mutate(year = year) %>% select(-game) %>% rename(last = name)
}x1 <- get_pl('400829015', 2016)
m <- players %>% filter(From <= 2016, To >= 2016) %>%
select(name, last, first, f_init)
x1 %>% left_join(m, by = c('last', 'f_init')) %>% as.data.frame()## f_init last pos year name first
## 1 C Landry PF 2016 Carl Landry Carl
## 2 J Grant SF 2016 Jerami Grant Jerami
## 3 J Grant SF 2016 Jerian Grant Jerian
## 4 I Canaan PG 2016 Isaiah Canaan Isaiah
## 5 I Smith PG 2016 Ish Smith Ish
## 6 H Thompson SG 2016 Hollis Thompson Hollis
## 7 E Brand PF 2016 Elton Brand Elton
## 8 R Covington SF 2016 Robert Covington Robert
## 9 K Marshall PG 2016 Kendall Marshall Kendall
## 10 T.J McConnell PG 2016 <NA> <NA>
## 11 N Stauskas SG 2016 Nik Stauskas Nik
## 12 N Noel PF 2016 Nerlens Noel Nerlens
## 13 R Holmes PF 2016 Richaun Holmes Richaun
## 14 C Wood PF 2016 Christian Wood Christian
## 15 M Williams PF 2016 Marvin Williams Marvin
## 16 M Williams PF 2016 Mo Williams Mo
## 17 C Zeller C 2016 Cody Zeller Cody
## 18 K Walker PG 2016 Kemba Walker Kemba
## 19 N Batum SG 2016 Nicolas Batum Nicolas
## 20 C Lee SG 2016 Courtney Lee Courtney
## 21 F Kaminsky III C 2016 <NA> <NA>
## 22 A Jefferson C 2016 Al Jefferson Al
## 23 J Lin PG 2016 Jeremy Lin Jeremy
## 24 J Lamb SG 2016 Jeremy Lamb Jeremy
## 25 S Hawes PF 2016 Spencer Hawes Spencer
## 26 T Hansbrough PF 2016 Tyler Hansbrough Tyler
## 27 J Gutierrez PG 2016 Jorge Gutierrez Jorge
## 28 T Daniels SG 2016 Troy Daniels TroyThe fuzzyjoin package can help some here but still needs a few features to get us all the way to where we need to be.
x1 %>%
stringdist_left_join(m, max_dist = 1, by = c('last', 'f_init')) %>%
select(-year, -name) %>%
as.data.frame()## f_init.x last.x pos last.y first f_init.y
## 1 C Landry PF Landry Carl C
## 2 J Grant SF Grant Jerami J
## 3 J Grant SF Grant Jerian J
## 4 I Canaan PG Canaan Isaiah I
## 5 I Smith PG Smith Greg G
## 6 I Smith PG Smith Ish I
## 7 I Smith PG Smith J.R. J
## 8 I Smith PG Smith Jason J
## 9 I Smith PG Smith Josh J
## 10 I Smith PG Smith Russ R
## 11 H Thompson SG Thompson Hollis H
## 12 H Thompson SG Thompson Jason J
## 13 H Thompson SG Thompson Klay K
## 14 H Thompson SG Thompson Tristan T
## 15 E Brand PF Brand Elton E
## 16 R Covington SF Covington Robert R
## 17 K Marshall PG Marshall Kendall K
## 18 T.J McConnell PG <NA> <NA> <NA>
## 19 N Stauskas SG Stauskas Nik N
## 20 N Noel PF Noel Nerlens N
## 21 R Holmes PF Holmes Richaun R
## 22 C Wood PF Hood Rodney R
## 23 C Wood PF Wood Christian C
## 24 M Williams PF Williams Alan A
## 25 M Williams PF Williams Deron D
## 26 M Williams PF Williams Derrick D
## 27 M Williams PF Williams Elliot E
## 28 M Williams PF Williams Lou L
## 29 M Williams PF Williams Marvin M
## 30 M Williams PF Williams Mo M
## 31 C Zeller C Zeller Cody C
## 32 C Zeller C Zeller Tyler T
## 33 K Walker PG Walker Kemba K
## 34 N Batum SG Batum Nicolas N
## 35 C Lee SG Gee Alonzo A
## 36 C Lee SG Lee Courtney C
## 37 C Lee SG Lee David D
## 38 C Lee SG Len Alex A
## 39 F Kaminsky III C <NA> <NA> <NA>
## 40 A Jefferson C Jefferson Al A
## 41 A Jefferson C Jefferson Cory C
## 42 A Jefferson C Jefferson Richard R
## 43 J Lin PG Len Alex A
## 44 J Lin PG Lin Jeremy J
## 45 J Lamb SG Lamb Jeremy J
## 46 S Hawes PF Hawes Spencer S
## 47 S Hawes PF Hayes Chuck C
## 48 T Hansbrough PF Hansbrough Tyler T
## 49 J Gutierrez PG Gutierrez Jorge J
## 50 T Daniels SG Daniels Troy TWe get a ton of hits but this is do to the distance allowed being one. If we set it to less than one it turns into an exact match. In this case what we need is a way to have a different distance on each field to join on, or even a hiearchy of how we match on differnt fields. Then we need another method that actually uses the distance between two that we can use to create a link from all of the matches.
So in no way did I entirely solve this issue, but that was not really my goal. The goal was more to highlight some of the challanges and possible steps to solve them as well as getting aquanted with the intricacies of the problem.